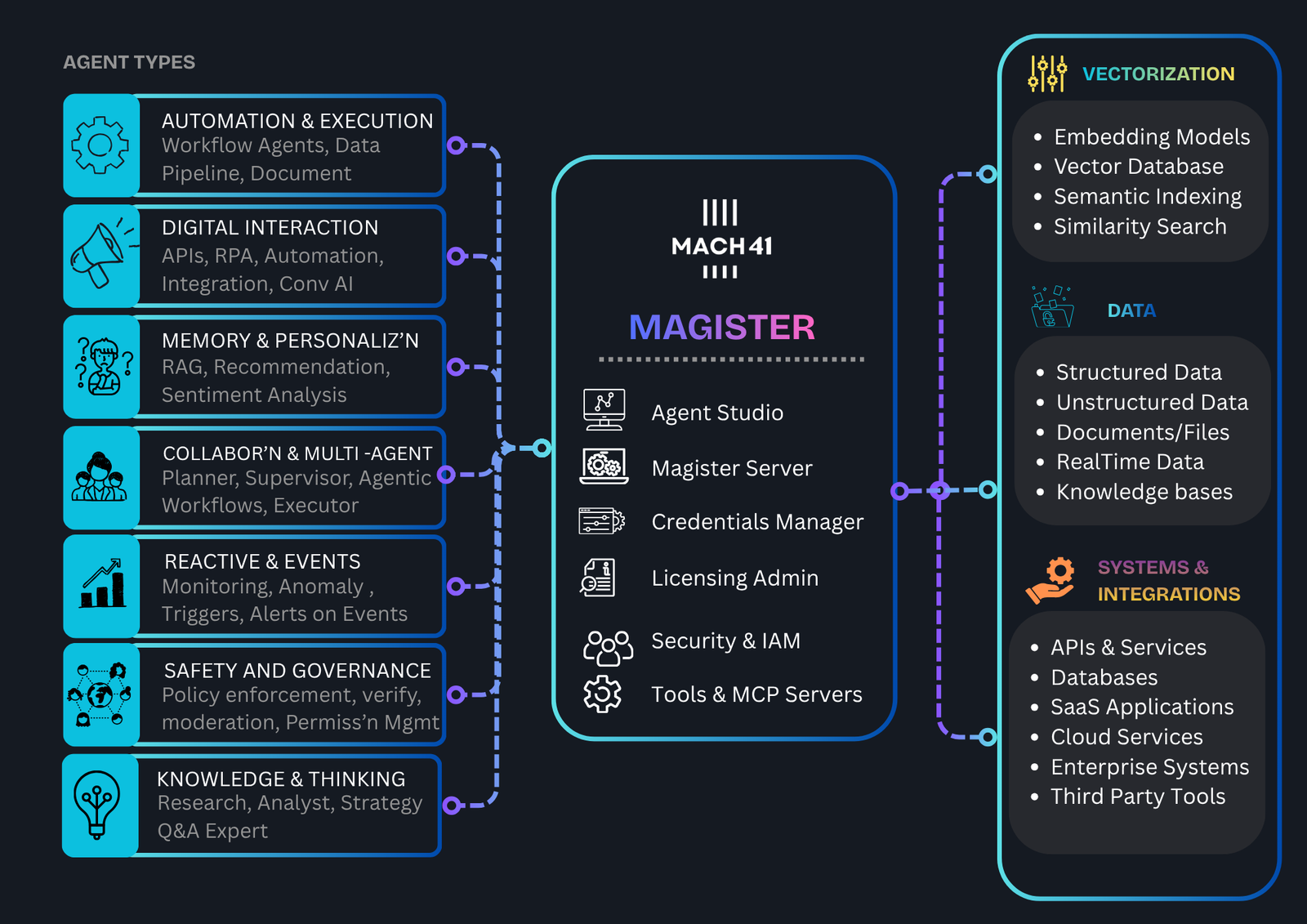
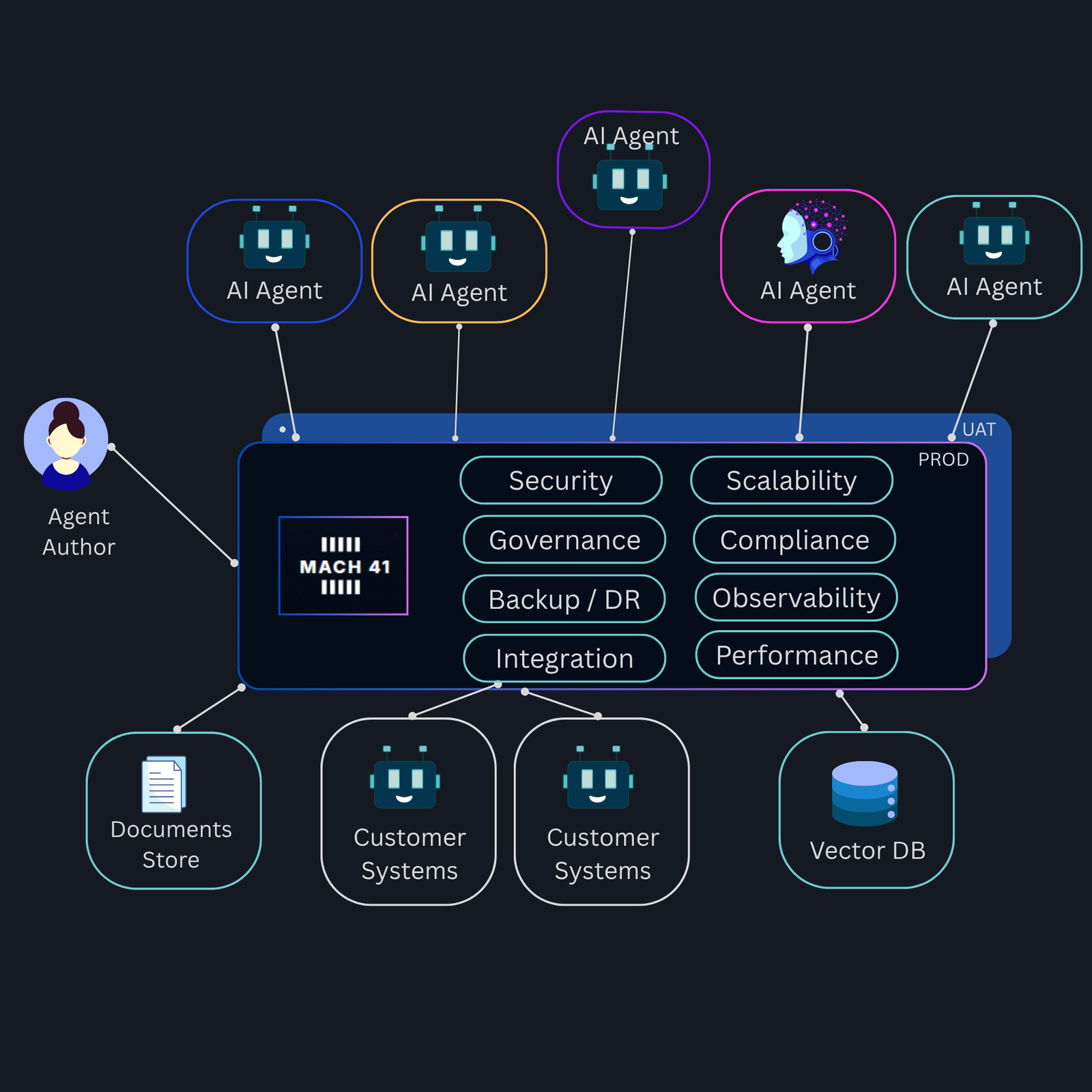
Magister :
AI Agents Execution Platform
Enterprise focused platform for "Building" & "Running" AI agents for Business.
Magister is a Enterprise ready Operating System for AI agents - with a Low code IDE for developing Agents with Natural Language + embedded Magister Bond integration toolkit.
Any LLM / Custom LLM
High Data Volume & Performance
Deploy
in minutes.
Sub-10ms
latency
120+
blueprints
300+
Magister Bond
14
AI-native nodes
100K
events/sec